In this PySpark tutorial, you’ll learn the fundamentals of Spark, how to create distributed data processing pipelines, and leverage its versatile libraries to transform and analyze large datasets efficiently with examples. I will also explain what is PySpark. its features, advantages, modules, packages, and how to use RDD & DataFrame with simple and easy examples from my working experience in Python code.
PySpark Tutorial Introduction
PySpark Tutorial – PySpark is an Apache Spark library written in Python to run Python applications using Apache Spark capabilities. Using PySpark we can run applications parallelly on the distributed cluster (multiple nodes).
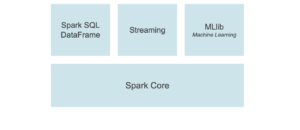
PySpark is an interface for Apache Spark in Python. It not only allows you to write Spark applications using Python APIs, but also provides the PySpark shell for interactively analyzing your data in a distributed environment. PySpark supports most of Spark’s features such as Spark SQL, DataFrame, Streaming, MLlib (Machine Learning) and Spark Core.
What is Apache Spark
Apache Spark is an open-source unified analytics engine used for large-scale data processing.
Spark can run on single-node machines or multi-node machines(Cluster). It was created to address the limitations of MapReduce, by doing in-memory processing. Spark reuses data by using an in-memory cache to speed up machine learning algorithms that repeatedly call a function on the same dataset. This lowers the latency making Spark multiple times faster than MapReduce, especially when doing machine learning, and interactive analytics. Apache Spark can also process real-time streaming.
It is also a multi-language engine, that provides APIs (Application Programming Interfaces) and libraries for several programming languages like Java, Scala, Python, and R, allowing developers to work with Spark using the language they are most comfortable with.
- Scala: Spark’s primary and native language is Scala. Many of Spark’s core components are written in Scala, and it provides the most extensive API for Spark.
- Java: Spark provides a Java API that allows developers to use Spark within Java applications. Java developers can access most of Spark’s functionality through this API.
- Python: Spark offers a Python API, called PySpark, which is popular among data scientists and developers who prefer Python for data analysis and machine learning tasks. PySpark provides a Pythonic way to interact with Spark.
- R: Spark also offers an R API, enabling R users to work with Spark data and perform distributed data analysis using their familiar R language.
What are the Features of PySpark?
The following are the main features of PySpark.
- In-memory computation
- Distributed processing using parallelize
- Can be used with many cluster managers (Spark, Yarn, Mesos e.t.c)
- Fault-tolerant
- Immutable
- Lazy evaluation
- Cache & persistence
- Inbuild-optimization when using DataFrames
- Supports ANSI SQL
Advantages of PySpark
- PySpark is a general-purpose, in-memory, distributed processing engine that allows you to process data efficiently in a distributed fashion.
- Applications running on PySpark are 100x faster than traditional systems.
- You will get great benefits from using PySpark for data ingestion pipelines.
- Using PySpark we can process data from Hadoop HDFS, AWS S3, and many file systems.
- PySpark also is used to process real-time data using Streaming and Kafka.
- Using PySpark streaming you can also stream files from the file system and also stream from the socket.
- PySpark natively has machine learning and graph libraries.
What Version of Python PySpark Supports
PySpark 3.5 is compatible with Python 3.8 and newer, as well as R 3.5, Java versions 8, 11, and 17, and Scala versions 2.12 and 2.13, beyond. However, it’s important to note that support for Java 8 versions prior to 8u371 has been deprecated starting from Spark 3.5.0.
PySpark Architecture
Apache Spark works in a master-slave architecture where the master is called the “Driver” and slaves are called “Workers”. When you run a Spark application, Spark driver creates a context that is an entry point to your application, and all operations (transformations and actions) are executed on worker nodes, and the resources are managed by Cluster Manager.
